
ЧТО ТАКОЕ ВЕБ-АРХИВ И КАК ИМ ПОЛЬЗОВАТЬСЯ?
-
Post author

-
У самых посещаемых сайтов за весь период их существования может быть создано более 200 тыс. версий. Благодаря веб-архиву они не исчезают бесследно, а архивируются в интернете. Пользователи могут найти нужный контент, ранее опубликованный в сети, даже если он был удален. Исключение составляют те веб-ресурсы, владельцы которых установили запрет на архивирование страниц.
О чем идет речь?
- Что такое Web Archive и где хранится история интернета?
- Как работает Wayback Machine?
- Как запретить добавление сайта в веб-архив?
- Как восстановить сайт из Web Archive?
- Выводы
Что такое Web Archive и где хранится история интернета?
Веб-архив — это сервис, который собирает и хранит копии сайтов за разные даты. С момента основания в 1996 году в нем сохранено более 525 млрд веб-страниц, в том числе 28 млн книг, 14 млн аудиофайлов и 6 млн видео. Сайт web.archive.org входит в топ-150 самых популярных проектов мира.
Целью создателей веб-архива было решение проблемы постоянного и необратимого исчезновения контента на измененных или закрытых сайтах. Архив был разработан как сервис общего доступа ко всем знаниям в виде цифровых данных.
«Предпосылками развития вебархивирования стали проблемы вымирания ссылок и потенциальное наступление цифровых темных веков. В 1996 году создан «Архив Интернета» — первая некоммерческая организация, которая поставила своей целью создать «снимки» всех страниц в интернете. В 2001 году «Архив» запустил сервис по архивированию сайтов Wayback Machine, через который по состоянию на 2021 год было сохранено более 600 млрд веб-страниц». «Архивирование веб-сайтов», Википедия
Копии веб-страниц архивируются при сохранении вручную, а также при посещении сайтов вебкраулерами. Последних называют также пауками или ботами — эти программы переносят данные с веб-ресурсов в веб-архив. Аналогично происходит добавление содержимого сайтов в базу данных поисковиков.
С помощью интернет-архива можно узнать, как выглядел сайт в прошлом, выбрав конкретную дату, и это не единственное назначение Web Archive. Существует ряд других возможностей, которые открывает перед пользователями архив.
- Для дизайнеров, разработчиков сайтов, маркетологов, SEO-специалистов, ценным является понимание давно забытых трендов, требований поисковых систем, способов выделиться на рынке и др. Стоит проанализировать изменения на любом из популярных веб-ресурсов, чтобы узнать, какие нововведения «прижились» за определенный промежуток времени.
- Владельцы сайтов могут восстановить резервную копию веб-ресурса. А с помощью парсера можно сэкономить время и автоматизировать сбор информации в архиве.
- Журналисты, исследователи и все желающие могут найти в архиве уникальную информацию, которую удалили. Это могут быть, например, данные о медийных лицах, политических деятелях или событиях, удаленных с сайтов в результате цензуры.
- Историю веб-ресурса стоит проверять и перед покупкой домена. Важно, чтобы в прошлом на сайте не публиковался запрещенный или вредоносный контент.
- Можно восстановить ценные данные после взлома сайта хакерами.
«По состоянию на 4 февраля 2024 года в Интернет-архиве хранится более 44 миллионов печатных материалов, 10,6 миллиона видеозаписей, 1 миллион программных программ, 15 миллионов аудиофайлов, 4,8 миллиона изображений, 255 000 концертов и более 835 миллиардов веб-страниц в Wayback Machine. Его миссия — обязаться обеспечить «всеобщий доступ ко всем знаниям». Internet Archive, Wikipedia
Благодаря этому можно проследить историю изменения сайта с момента возникновения, найти информацию, которую удалили, и даже восстановить свой сайт, когда нет резервной копии.
Первой и самой известной организацией, которая хранит сайты и цифровые материалы в некоммерческих целях, является Internet Archive, основанная Брюстером Кейлом. Основным ее продуктом является сервис Wayback Machine. Инструмент сохраняет веб-страницы и позволяет изучать их эволюцию и, при необходимости, восстанавливать отдельные страницы или целые сайты. Кроме Internet Archive, история интернета хранится на серверах различных библиотек, архивов и государственных учреждений.
Чтобы воспользоваться возможностями Wayback Machine, нужно просто зайти на сайт web.archive.org. На нем размещены копии страниц, которые начали создаваться с 1998 года.
📌 Читайте статью: Анализ скорости сайта: как ускорить загрузку сайта
Какие еще есть интернет-архивы?
- Archive.today работает с 2012 года. В отличие от Wayback Machine, он не использует поисковых роботов и архивирует страницы только по запросу пользователей. Сайт имеет несколько зеркал, в частности archive.is, archive.li, archive.ph.
- Library of Congress содержит значительное количество цифровых материалов, которые отражают культурное, историческое и политическое наследие США и мира.
- Perma.cc — это некоммерческий сервис, который сохраняет интернет-источники для цитирования в научных работах. Он создан специально для академических, научных и правовых организаций.
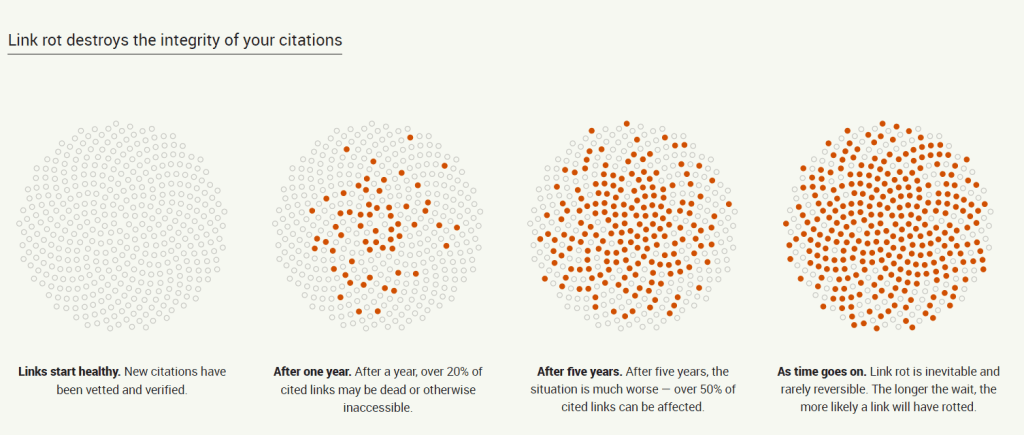
На сайте Perma.cc продемонстрировано, как быстро происходит повреждение ссылок на сайте: через год после создания сайта более 20% ссылок могут быть недоступны, а через 5 лет более 50%. Это подтверждает необходимость добавления страниц в веб-архив.
Как работает Wayback Machine?
Рассмотрим возможности web.archive.org на примере анализа сайта forbes.ua. Видим, что копии сайта начали создаваться впервые еще с самого начала функционирования Wayback Machine. Больше всего — с 2021 года и до сих пор. Это заметно на графике хронологии архивирования веб-страниц.
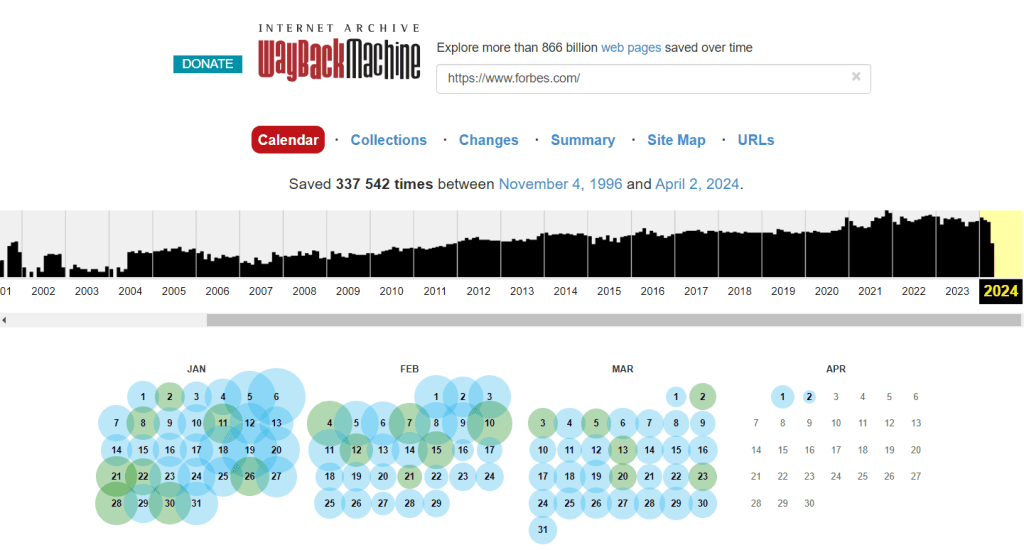
Размер голубых точек, которыми обозначены сохранения, отображает количество копий, созданных в конкретную дату. Чем больше диаметр, тем больше архивирования сайта было выполнено в этот день. Об успешном создании копий свидетельствует и зеленый цвет. А вот оранжевый указывает на допущенные во время архивации ошибки. О наличии критических ошибок при попытках архивирования свидетельствует красная окраска.
Следовательно, для просмотра оптимально выбирать голубые точки. Выберем для нашего сайта одну из них, например, за 4 июня 2014 г. Если нажать на этот день в календаре архива, открывается страница сайта, какой она была в то время, при этом все ссылки активны. В некоторых случаях можно выбрать точное время сканирования из нескольких предложенных сервисом вариантов.
Отсюда можем перейти к любой другой дате. Например, вот так выглядела эта же страница новостей в августе 2022 года.
Если необходимо посмотреть архивную копию страницы за определенную дату, введите в поиск Google запрос по шаблону http://web.archive.org/web/20210323/https://forbes.com, где 20220224 — год, месяц и день, а https://www.forbes.com — адрес нужного вам сайта.
Посетители сайта Wayback Machine могут воспользоваться предложенными сервисом инструментами:
- Calendar
- Collections
- Changes
- Summary
- Site Map
- URLs
📌 Что такое: Что такое GDPR, персональные данные и cookie
Например, инструмент «Коллекции» демонстрирует причины архивации различных URL-адресов. Коллекциями в данном случае называют группы сканирования, которые имеют определенные цели или направлены на конкретные группы доменов, например, страницы с неработающими ссылками или региональные веб-ресурсы.
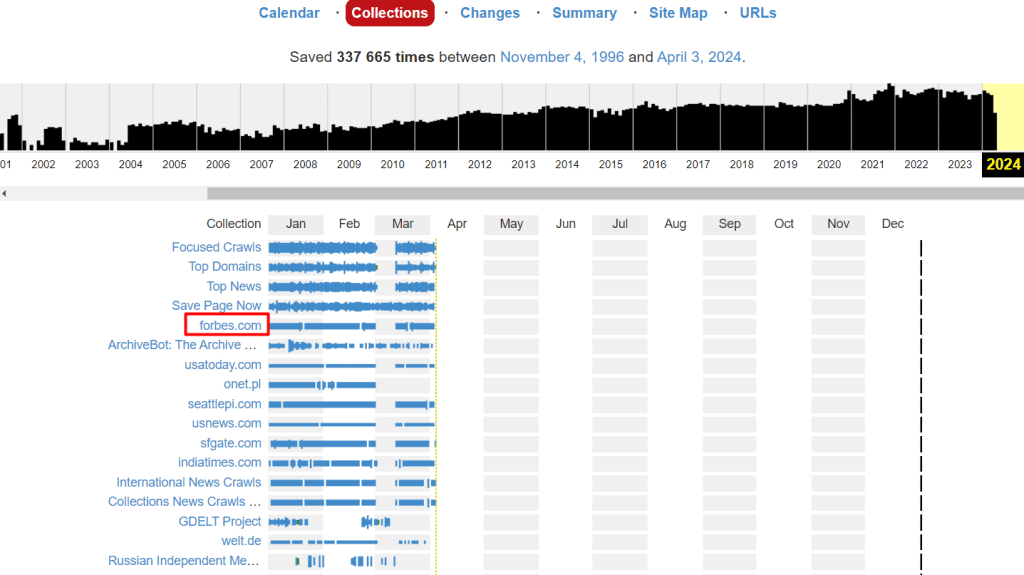
Чтобы рассмотреть дополнительную информацию о той или иной коллекции, нажмите на нее.
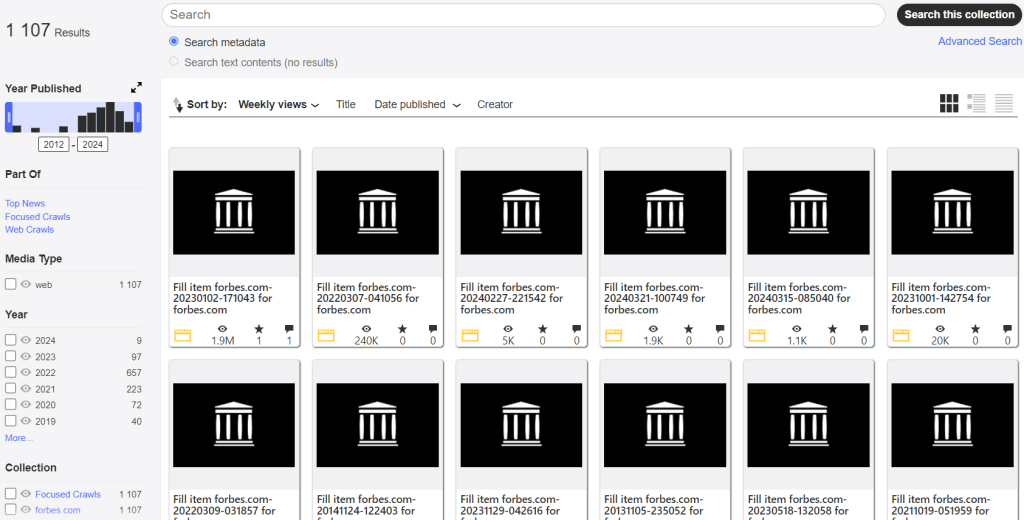
Следующий инструмент — Changes. Он позволяет ознакомиться с изменениями в содержимом заархивированных страниц. Голубым обозначен добавленный контент, желтым — удаленный.
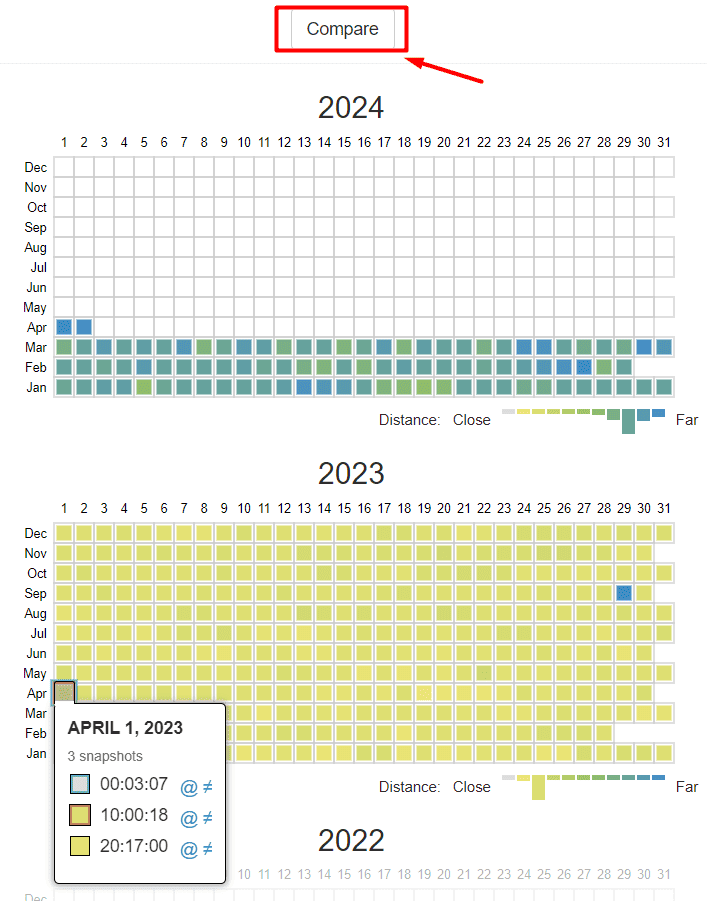
Нужно выбрать две даты для сравнения и нажать кнопку Compare. Вы сможете рассмотреть одновременно два варианта страницы за 1 апреля 2022 года и за эту же дату 2023 года.
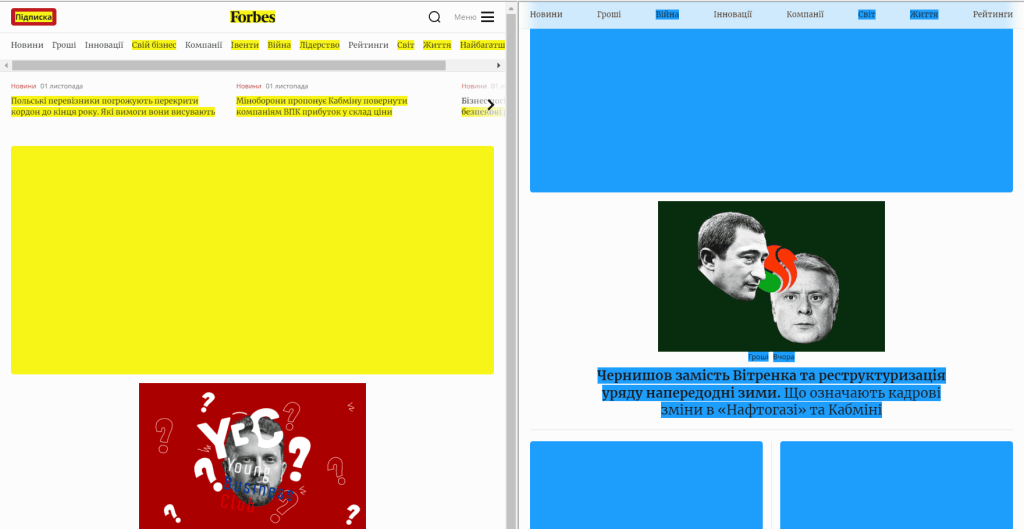
Вместо адреса страницы можно вводить поисковый запрос, в таком случае сервис выдаст страницы сохраненных сайтов на данную тематику.
Инструмент Summary позволяет ознакомиться со статистикой за любой промежуток времени, которая представлена в виде графиков и таблиц.
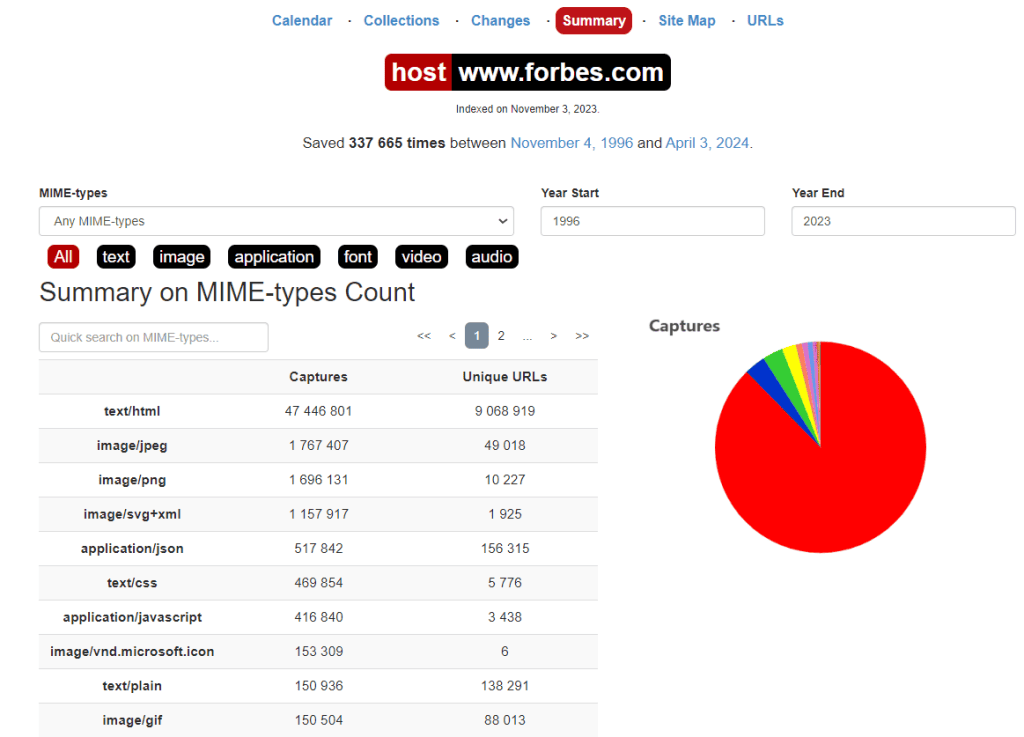
Инструмент Site Map демонстрирует данные в виде визуальной карты сайта с диаграммой для каждого года. Центральный круг является «корнем» сайта, а последующие кольца последовательно представляют различные страницы сайта.
Чтобы перейти к архиву определенного URL-адреса, следует просто нажать на нужный участок.
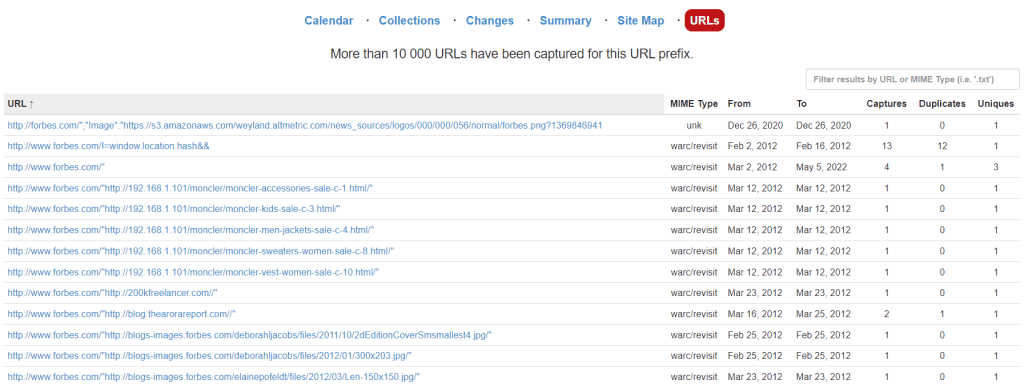
Последняя вкладка под названием URLs показывает, сколько уникальных файлов содержится в архиве.
Как запретить добавление сайта в веб-архив?
Владелец сайта может запретить его добавление в веб-архив. Часто это делается с целью предотвращения незаконного копирования контента или перед продажей доменного имени. Для запрета следует обратиться в службу поддержки веб-архива или использовать файл robots.txt. Кроме этого, вебкраулеры не посещают сайты, которые защищены паролем.
В первом случае нужно отправить запрос на адрес info@archive.org, указав доменное имя в тексте сообщения.
Добавление в файл robots.txt специальной директивы блокирует доступ для веб-краулеров, однако предыдущие заархивированные страницы будут оставаться доступными в Wayback Machine. Пользователи все равно смогут посмотреть, как сайт выглядел раньше.
Директива для запрета доступа вебкраулеров выглядит следующим образом:
User-agent: ia_archiver
Disallow: /
User-agent: ia_archiver-web.archive.org
Disallow: /
Помните о том, что файл robots.txt должен находиться в корневом каталоге домена.
Как восстановить сайт из Web Archive?
Чтобы создать копию URL-адреса и добавить его в архив, нужно ввести нужную ссылку на главной странице Wayback Machine и нажать «Save page».
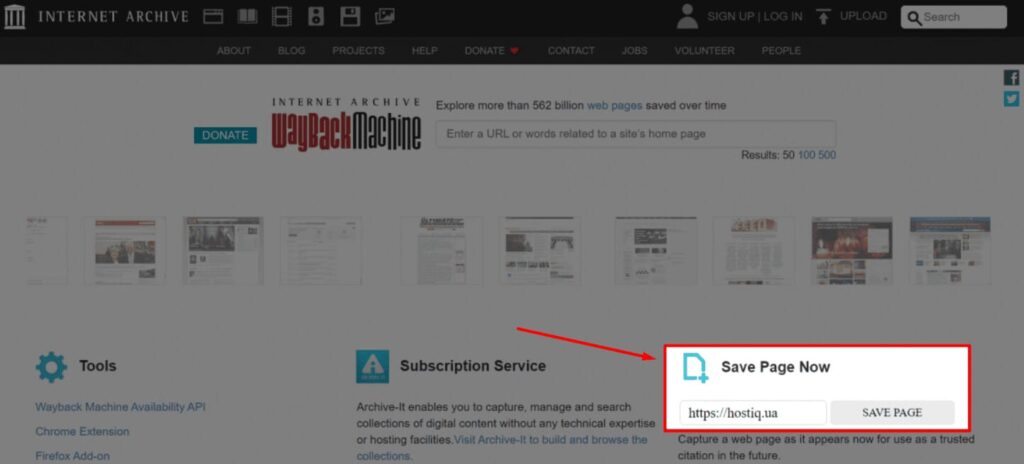
Желательно делать это перед внесением серьезных изменений на сайте. Благодаря этому вы сможете восстановить веб-ресурс через архив в случае сбоя, взлома хакерами или потери данных.
Конечно, создавать копию всего сайта постранично — слишком длительная и рутинная работа. Интернет-архив предлагает для автоматизации этого процесса платный сервис Archive It.
Если страницу удалили раньше, чем она смогла попасть в веб-архив, можно найти ее в кэше Google. Для этого нужно ввести в адресную строку ссылку типа cache:URL, где URL — адрес страницы, которая вам нужна. Например,
cache:https://www.forbes.com
Однако этот метод хранения не является совершенным, ведь в кэше хранится только самая актуальная копия каждой страницы. Поисковый робот постоянно заменяет старые версии страниц новыми, это может происходить как ежедневно, так и по крайней мере дважды в месяц.
Если вам нужна копия только одной или нескольких страниц, вы можете вручную скопировать текст и код страниц, а также сохранить изображения. Чтобы сохранить код страницы, перейдите на нее в Wayback Machine, нажмите правой кнопкой мыши и выберите «View page source». Скопируйте код и вставьте его в текстовый редактор, где вы можете сохранить его как HTML-файл.
Существуют также специальные скрипты, которые позволяют восстанавливать все содержимое сайта за один раз:
- Wayback Machine Scraper;
- Wayback Scraper;
- Hartator Wayback Machine Downloader (Ruby).
Некоторые платные сторонние службы, такие как Wayback Machine Downloader, помогают с восстановлением сайта из веб-архива. Обычно протестировать их функционал можно бесплатно.
Бывают ситуации, когда ресурс доступен, но в копии отсутствуют картинки, или нет фрагмента контента. Это может быть связано с тем, что сайт был заархивирован Wayback Machine лишь частично. Возможно, версия сайта за другую дату или время будет более целостная.
Выводы
Веб-архивы позволяют хранить и воспроизводить историю интернета. Они обеспечивают доступ к старым версиям веб-страниц и других цифровых материалов для исследований, анализа и общего пользования. Часто это пригодится после серьезных хакерских атак на важные сайты.
Архив интернета — это некоммерческая библиотека книг, программного обеспечения, сайтов, аудио- и видеозаписей. Наиболее популярным является бесплатный веб-архив Wayback Machine. Копии интернет-страниц появляются в нем при сохранении вручную и благодаря сканированию веб-краулерами (специальными программами).
Отдельные частные компании и организации могут иметь собственные системы архивирования для внутреннего использования или для коммерческих целей.
Частые вопросы
Веб-архив — это коллекция сайтов, которые были сохранены в исторических или справочных целях. Эти архивы фиксируют содержимое веб-страниц в разные моменты времени, позволяя пользователям просматривать более старые версии веб-ресурсов или страниц, которые могут больше не существовать в интернете.
Чтобы зайти в веб-архив, нужно посетить сайт web.archive.org.
Пользователи могут посетить сайт Wayback Machine и ввести URL веб-страницы, которую они хотят просмотреть. После этого сервис осуществит поиск в своей базе данных и отобразит календарь доступных дат. Вы можете выбрать день и время, чтобы просмотреть архивную версию страницы в том виде, в котором она появилась именно тогда.
История интернета хранится на различных ресурсах организаций, которые занимаются хранением цифрового контента и архивированием веб-страниц. Одним из самых известных и крупнейших хранителей истории интернета является некоммерческая организация Internet Archive, ключевым продуктом которой является Wayback Machine.
Отсканированные Web Archive страницы хранятся на серверах интернет-архива, где они упорядочены по URL-адресу, по дате и времени.
Wayback Machine непрерывно сканирует интернет, посещая веб-сайты и индексируя их содержимое. Когда Wayback Machine наталкивается на веб-страницу, она делает снимок или скриншот ее содержимого, включая текст, изображения и другие мультимедийные элементы.
-
Tags