
ЩО ТАКЕ ВЕБ-АРХІВ І ЯК ЇМ КОРИСТУВАТИСЯ?
-
Post author

-
У найвідвідуваніших сайтів за весь період їх існування може бути створено більше 200 тис. версій. Завдяки веб-архіву вони не зникають безслідно, а архівуються в інтернеті. Користувачі можуть знайти потрібний контент, раніше опублікований у мережі, навіть якщо його було видалено. Виняток становлять ті веб-ресурси, власники яких встановили заборону на архівування сторінок.
Про що йде мова?
- Що таке Web Archive та де зберігається історія інтернету?
- Як працює Wayback Machine?
- Як заборонити додавання сайту до веб-архіву?
- Як відновити сайт з Web Archive?
- Висновки
Що таке Web Archive та де зберігається історія інтернету?
Веб-архів — це сервіс, який збирає і зберігає копії сайтів за різні дати. З моменту заснування у 1996 році у ньому збережено понад 525 млрд веб-сторінок, у тому числі 28 млн книжок, 14 млн аудіофайлів і 6 млн відео. Сайт web.archive.org входить у топ-150 найпопулярніших проєктів світу.
Метою творців веб-архіву було вирішення проблеми постійного та незворотного зникнення контенту на змінених чи закритих сайтах. Архів був розроблений як сервіс загального доступу до всіх знань у вигляді цифрових даних.
«Передумовами розвитку вебархівування стали проблеми вимирання посилань і потенційний наступ цифрових темних століть. 1996 року створено «Архів Інтернету» — першу некомерційну організацію, яка поставила собі за мету створити «знімки» всіх сторінок в інтернеті. 2001 року «Архів» запустив сервіс із архівування сайтів Wayback Machine, через який станом на 2021 рік було збережено понад 600 млрд вебсторінок». «Архівування вебсайтів», Вікіпедія
Копії веб-сторінок архівуються при збереженні вручну, а також при відвідуванні сайтів вебкраулерами. Останніх називають також павуками чи ботами — ці програми переносять дані з веб-ресурсів у веб-архів. Аналогічно відбувається додавання вмісту сайтів у базу даних пошуковиків.
За допомогою інтернет-архіву можна дізнатися, як виглядав сайт у минулому, обравши конкретну дату, і це не єдине призначення Web Archive. Існує ряд інших можливостей, котрі відкриває перед користувачами архів.
- Для дизайнерів, розробників сайтів, маркетологів, SEO-спеціалістів, цінним є розуміння давно забутих трендів, вимог пошукових систем, способів виділитися на ринку і ін. Варто проаналізувати зміни на будь-якому з популярних веб-ресурсів, щоб дізнатися, які нововведення «прижилися» за певний проміжок часу.
- Власники сайтів мають змогу відновити резервну копію веб-ресурсу. А за допомогою парсера можна зекономити час і автоматизувати збір інформації в архіві.
- Журналісти, дослідники та всі бажаючі можуть знайти в архіві унікальну інформацію, яку видалили. Це можуть бути, наприклад, дані про медійних осіб, політичних діячів чи події, видалені з сайтів унаслідок цензури.
- Історію веб-ресурсу варто перевіряти і перед покупкою домену. Важливо, щоб у минулому на сайті не публікувався заборонений чи шкідливий контент.
- Можна відновити цінні дані після зламування сайту хакерами.
«Станом на 4 лютого 2024 року в Інтернет-архіві зберігається понад 44 мільйони друкованих матеріалів, 10,6 мільйона відеозаписів, 1 мільйон програмних програм, 15 мільйонів аудіофайлів, 4,8 мільйона зображень, 255 000 концертів та понад 835 мільярдів веб-сторінок у Wayback Machine. Його місія — зобов’язатись забезпечити «всезагальний доступ до всіх знань». Internet Archive, Wikipedia
Завдяки цьому можна простежити історію зміни сайту з моменту виникнення, знайти інформацію, яку видалили, і навіть відновити свій сайт, коли немає резервної копії.
Першою та найвідомішою організацією, яка зберігає сайти та цифрові матеріали в некомерційних цілях, є Internet Archive, заснована Брюстером Кейлом. Основним її продуктом є сервіс Wayback Machine. Інструмент зберігає веб-сторінки і дозволяє вивчати їх еволюцію та, за потреби, відновлювати окремі сторінки чи цілі сайти. Крім Internet Archive, історія інтернету зберігається на серверах різноманітних бібліотек, архівів і державних установ.
Щоб скористатися можливостями Wayback Machine, потрібно просто зайти на сайт web.archive.org. На ньому розміщені копії сторінок, що почали створюватися з 1998 року.
📌 Читайте статтю: Аналіз швидкості сайту: як пришвидшити завантаження сайту
Які ще є інтернет-архіви?
- Archive.today працює з 2012 року. На відміну від Wayback Machine, він не використовує пошукових роботів і архівує сторінки тільки за запитом користувачів. Сайт має кілька дзеркал, зокрема archive.is, archive.li, archive.ph.
- Library of Congress містить значну кількість цифрових матеріалів, які відображають культурну, історичну та політичну спадщину США та світу.
- Perma.cc — це некомерційний сервіс, що зберігає інтернет-джерела для цитування у наукових роботах. Він створений спеціально для академічних, наукових та правових організацій.
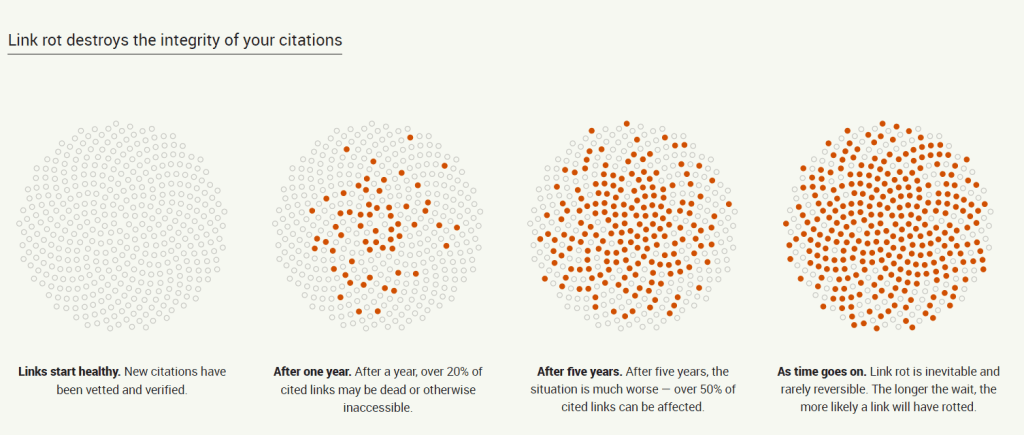
На сайті Perma.cc продемонстровано, як швидко відбувається пошкодження посилань на сайті: через рік після створення сайту понад 20% посилань можуть бути недоступними, а через 5 років — понад 50%. Це підтверджує необхідність додавання сторінок у веб-архів.
Як працює Wayback Machine?
Розглянемо можливості web.archive.org на прикладі аналізу сайту forbes.ua. Бачимо, що копії сайту почали створюватися вперше ще з самого початку функціонування Wayback Machine. Найбільше — з 2021 року і дотепер. Це помітно на графіку хронології архівування веб-сторінок.
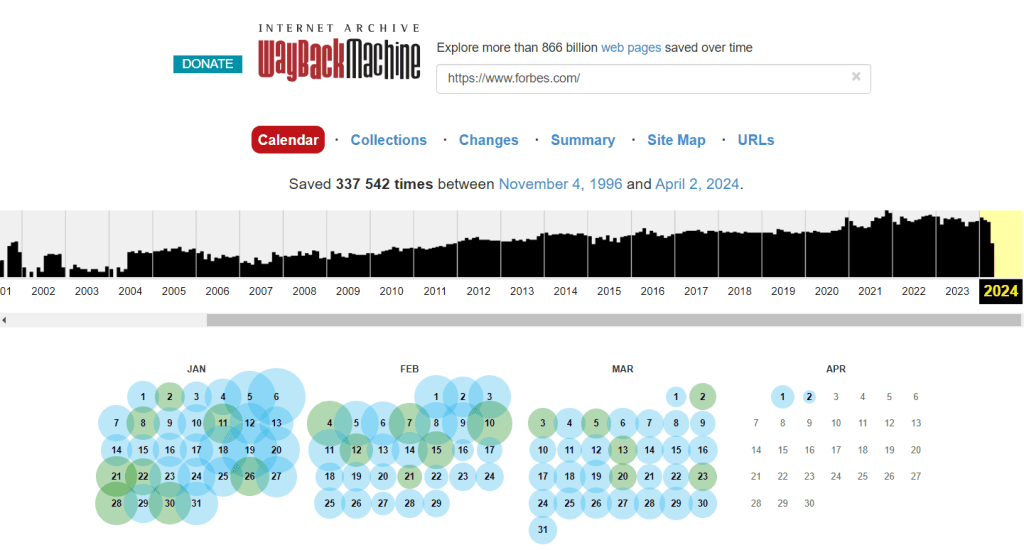
Розмір блакитних точок, якими позначені збереження, відображає кількість копій, створених у конкретну дату. Чим більший діаметр, тим більше архівування сайту було виконано в цей день. Про успішне створення копій свідчить і зелений колір. А от оранжевий вказує на допущені під час архівації помилки. Про наявність критичних помилок під час спроб архівування свідчить червоне забарвлення.
Отже, для перегляду оптимально вибирати блакитні точки. Виберемо для нашого сайту одну з них, наприклад, за 4 червня 2014 р. Якщо натиснути на цей день у календарі архіву, відкривається сторінка сайту, якою вона була в той час, при цьому всі посилання є активними. У деяких випадках можна обрати точний час сканування з кількох запропонованих сервісом варіантів.
Звідси можемо перейти до будь-якої іншої дати. Наприклад, ось так виглядала ця ж сторінка новин у серпні 2022 року.
Якщо необхідно подивитися архівну копію сторінки за певну дату, введіть у пошук Google запит за шаблоном http://web.archive.org/web/20210323/https://forbes.com, де 20220224 — рік, місяць і день, а https://www.forbes.com — адреса потрібного вам сайту.
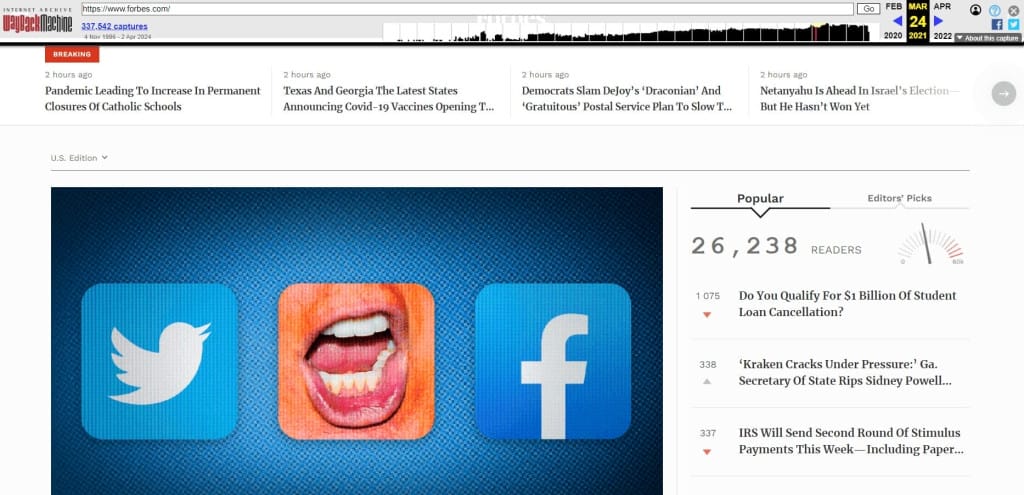
Відвідувачі сайту Wayback Machine можуть скористатися запропонованими сервісом інструментами:
- Calendar
- Collections
- Changes
- Summary
- Site Map
- URLs
📌 Читайте статтю: Що таке GDPR, персональні дані та cookie
Наприклад, інструмент «Колекції» демонструє причини архівації різних URL-адрес. Колекціями у даному випадку називають групи сканування, які мають певні цілі або спрямовані на конкретні групи доменів, наприклад,сторінки з непрацюючими посиланнями або регіональні веб-ресурси.
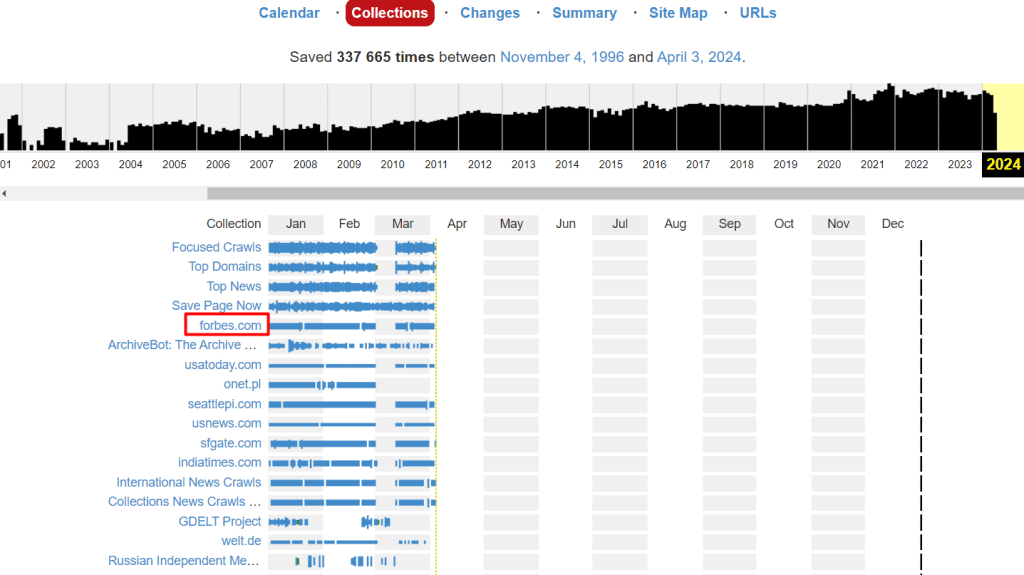
Щоб розглянути додаткову інформацію про ту чи іншу колекцію, натисніть на неї.
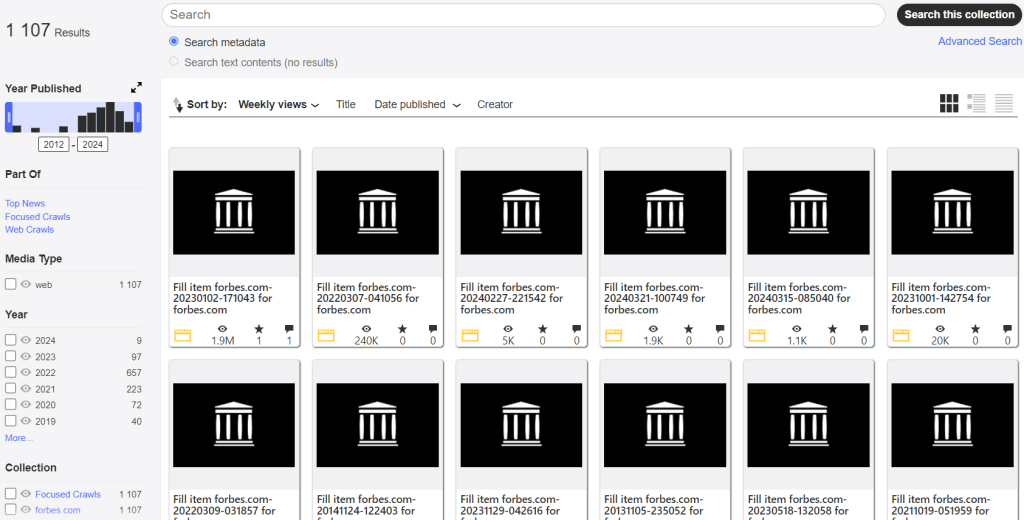
Наступний інструмент — Changes. Він дозволяє ознайомитися зі змінами у вмісті заархівованих сторінок. Блакитним позначений доданий контент, жовтим — видалений.
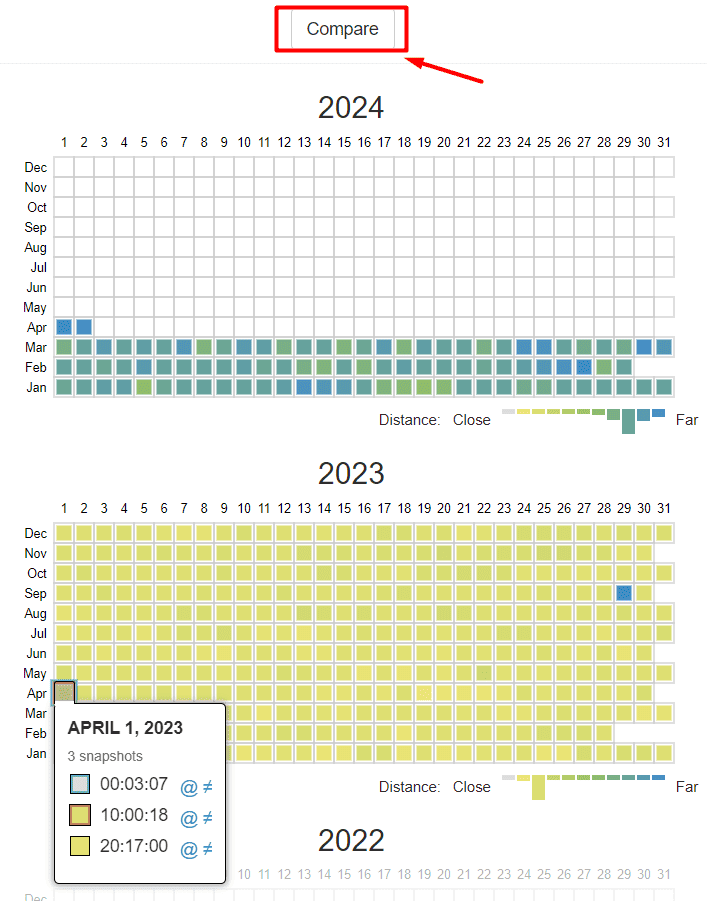
Потрібно обрати дві дати для порівняння та натиснути кнопку Compare. Ви зможете розглянути одночасно два варіанти сторінки за 1 квітня 2022 року і за цю ж дату 2023 року.
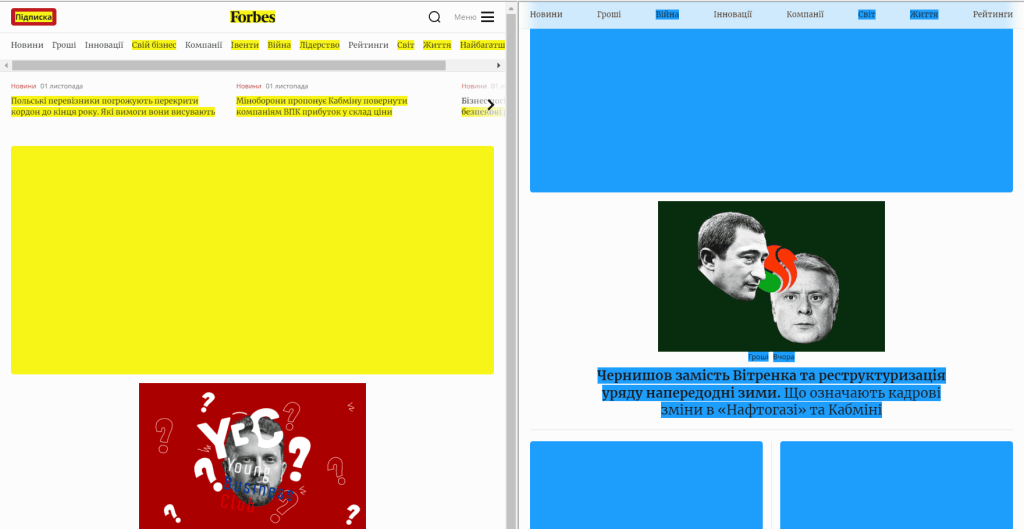
Замість адреси сторінки можна вводити пошуковий запит, у такому випадку сервіс видасть сторінки збережених сайтів на дану тематику.
Інструмент Summary дає змогу ознайомитися зі статистикою за будь-який проміжок часу, яка представлена у вигляді графіків і таблиць.
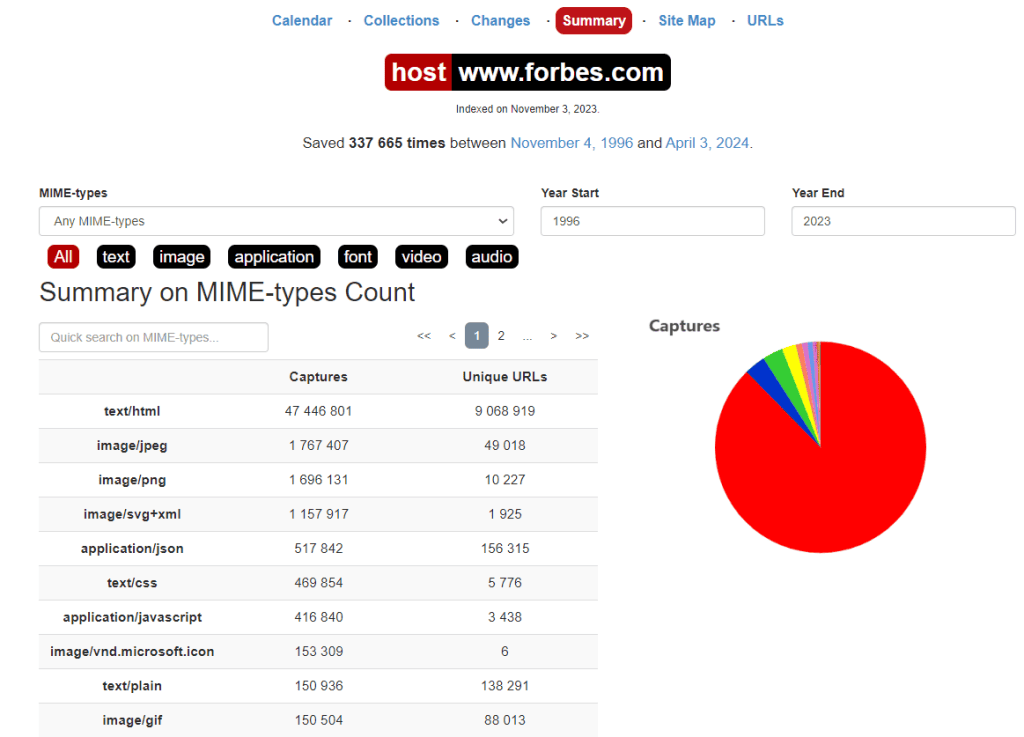
Інструмент Site Map демонструє дані у вигляді візуальної карти сайту з діаграмою для кожного року. Центральне коло є «коренем» сайту, а наступні кільця послідовно представляють різні сторінки сайту.
Щоб перейти до архіву певної URL-адреси, слід просто натиснути на потрібну ділянку.
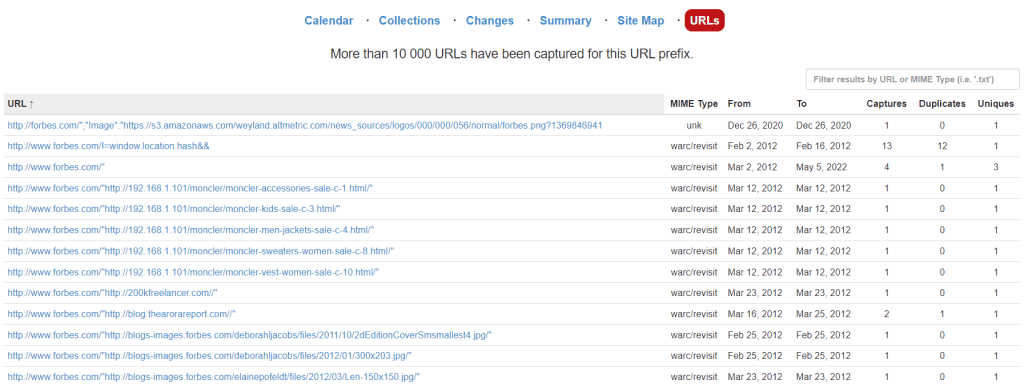
Остання вкладка під назвою URLs показує, скільки унікальних файлів міститься в архіві.
Як заборонити додавання сайту до веб-архіву?
Власник сайту може заборонити його додавання у веб-архів. Часто це робиться з метою запобігання незаконного копіювання контенту або перед продажем доменного імені. Для заборони слід звернутися у службу підтримки веб-архіву або використовувати файл robots.txt. Окрім цього, вебкраулери не відвідують сайти, які захищені паролем.
У першому випадку потрібно надіслати запит на адресу info@archive.org, вказавши доменне ім’я у тексті повідомлення.
Додавання у файл robots.txt спеціальної директиви блокує доступ для веб-краулерів, однак попередні заархівовані сторінки залишатимуться доступними у Wayback Machine. Користувачі все рівно зможуть подивитися, як сайт виглядав раніше.
Директива для заборони доступу вебкраулерів виглядає наступним чином:
User-agent: ia_archiver
Disallow: /
User-agent: ia_archiver-web.archive.org
Disallow: /
Пам’ятайте про те, що файл robots.txt повинен знаходитися у кореневому каталозі домену.
Як відновити сайт з Web Archive?
Щоб створити копію URL-адреси та додати її у архів, потрібно ввести потрібне посилання на головній сторінці Wayback Machine і натиснути «Save page».
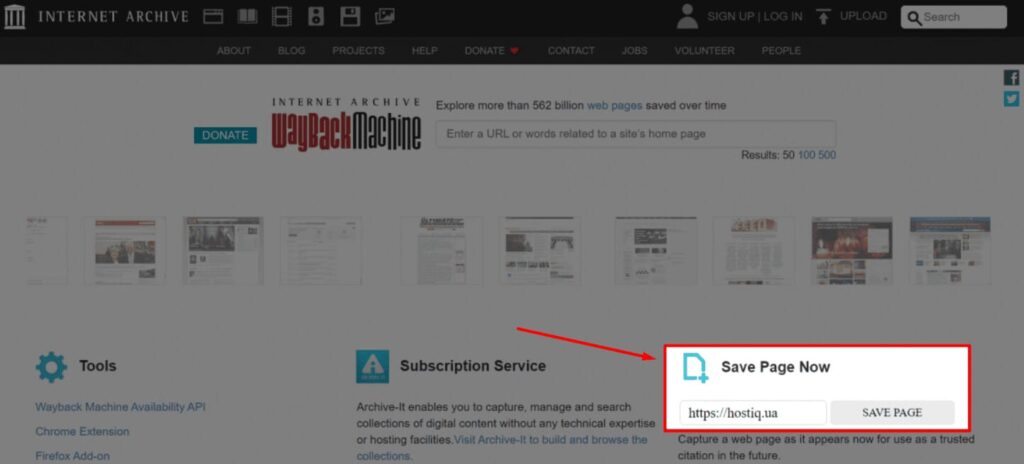
Бажано робити це перед внесенням серйозних змін на сайті. Завдяки цьому ви зможете відновити веб-ресурс через архів у разі збою, зламування хакерами або втрати даних.
Звісно, створювати копію всього сайту посторінково — надто тривала і рутинна робота. Інтернет-архів пропонує для автоматизації цього процесу платний сервіс Archive It.
Якщо сторінку видалили раніше, ніж вона змогла потрапити до веб-архіву, можна знайти її у кеші Google. Для цього потрібно ввести в адресний рядок посилання типу cache:URL, де URL — адреса сторінки, яка вам потрібна. Наприклад,
cache:https://www.forbes.com
Однак цей метод зберігання не є досконалим, адже у кеші зберігається тільки найактуальніша копія кожної сторінки. Пошуковий робот постійно замінює старі версії сторінок новими, це може відбуватися як щодня, так і принаймні двічі на місяць.
Якщо вам потрібна копія лише однієї або декількох сторінок, ви можете вручну скопіювати текст і код сторінок, а також зберегти зображення. Щоб зберегти код сторінки, перейдіть на неї у Wayback Machine, натисніть правою кнопкою миші та виберіть «View page source». Скопіюйте код і вставте його в текстовий редактор, де ви можете зберегти його як HTML-файл.
Існують також спеціальні скрипти, які дозволяють відновлювати весь вміст сайту за один раз:
- Wayback Machine Scraper;
- Wayback Scraper;
- Hartator Wayback Machine Downloader (Ruby).
Деякі платні сторонні служби, такі як Wayback Machine Downloader, допомагають з відновленням сайту з веб-архіву. Зазвичай протестувати їхній функціонал можна безкоштовно.
Трапляються ситуації, коли ресурс доступний, але у копії відсутні картинки, або немає фрагменту контенту. Це може бути пов’язане з тим, що сайт був заархівований Wayback Machine лише частково. Можливо, версія сайту за іншу дату чи час буде більш цілісна.
Висновки
Веб-архіви дозволяють зберігати та відтворювати історію інтернету. Вони забезпечують доступ до старих версій веб-сторінок та інших цифрових матеріалів для досліджень, аналізу та загального користування. Часто це стає в нагоді після серйозних хакерських атак на важливі сайти.
Архів інтернету — це некомерційна бібліотека книг, програмного забезпечення, сайтів, аудіо- і відеозаписів. Найбільш популярним є безкоштовний веб-архів Wayback Machine. Копії інтернет-сторінок з’являються у ньому при збереженні вручну та завдяки скануванню веб-краулерами (спеціальними програмами).
Окремі приватні компанії та організації можуть мати власні системи архівування для внутрішнього використання або для комерційних цілей.
Часті питання
Веб-архів — це колекція сайтів, які були збережені в історичних або довідкових цілях. Ці архіви фіксують вміст веб-сторінок у різні моменти часу, дозволяючи користувачам переглядати старіші версії веб-ресурсів або сторінок, які можуть більше не існувати в інтернеті.
Щоб зайти у веб-архів, потрібно відвідати сайт web.archive.org.
Користувачі можуть відвідати сайт Wayback Machine і ввести URL веб-сторінки, яку вони хочуть переглянути. Після цього сервіс здійснить пошук у своїй базі даних і відобразить календар доступних дат. Ви можете вибрати день і час, щоб переглянути архівну версію сторінки у тому вигляді, в якому вона з’явилася саме тоді.
Історія інтернету зберігається на різних ресурсах організацій, які займаються зберіганням цифрового контенту та архівуванням веб-сторінок. Одним із найвідоміших і найбільших зберігачів історії інтернету є некомерційна організація Internet Archive, ключовим продуктом якої є Wayback Machine.
Відскановані Web Archive сторінки зберігаються на серверах інтернет-архіву, де вони впорядковані за URL-адресою, за датою і часом.
Wayback Machine безперервно сканує інтернет, відвідуючи веб-сайти та індексуючи їхній вміст. Коли Wayback Machine натрапляє на веб-сторінку, вона робить знімок або скріншот її вмісту, включаючи текст, зображення та інші мультимедійні елементи.
-
Tags