
ЧТО ТАКОЕ GOOGLE SUPPLEMENTAL INDEX ИЛИ «СОПЛИ ГУГЛ»
-
Post author

-
Представьте, что вы заходите в магазин одежды. На вешалках и манекенах — новинки. На полках лежат аккуратно сложенные товары из предыдущих коллекций. Есть столик с акционными товарами, их также отлично видно. Наиболее заметны сезонные предложения. И мало кто догадывается, что на складе хранятся позиции, которые уже давно не рекламируются. Их можно купить, но об этой одежде никто не спрашивает, потому что она спрятана. Для магазина значительно выгоднее освободить место для популярной одежды, которая принесет бренду прибыль.
В течение длительного периода аналогичной была ситуация с дополнительным индексом поисковых систем. Google и другие поисковики прятали веб-страницы, которые не соответствовали важным критериям качества. Страницы могли быть слишком старыми, неинтересными, дублированными. И если таких на сайте было слишком много — это влияло на ранжирование веб-ресурса в целом.
О чем идет речь?
Основной индекс и дополнительный индекс Google
До 2007 года существовала вторичная база данных — GoogleSupplemental Index (SI). Рассмотрим факторы, которые влияли на попадание веб-страниц в хранилище поисковиков и которые стоит знать владельцам сайтов и SEO-специалистам и сегодня.Определить наличие страниц в дополнительном индексе когда-то можно было с помощью оператора site, который используется с URL-адресом сайта, например: site: marketing.link. Однако сейчас таким образом мы можем увидеть лишь количество проиндексированных страниц — если пролистываем выдачу Google по нашему запросу до конца.
Ранее поисковая система выводила на последней странице выдачи сообщение о том, что часть результатов по запросу скрыта.
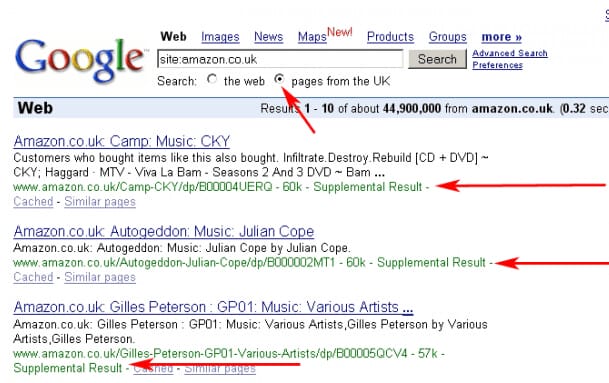
Так выглядел дополнительный индекс раньше.
Однако с 2006 года Google полностью изменил свой подход к сканированию и индексации дополнительных результатов.
«… мы индексируем URL-адреса с большим количеством параметров и продолжаем накладывать меньше ограничений на сайты, которые мы сканируем. Как следствие, Дополнительные результаты обновлены и полнее, чем когда-либо. Мы также работаем над тем, чтобы показывать больше Дополнительных результатов, гарантируя, что каждый запрос может осуществлять поиск в дополнительном индексе, и планируем развернуть это в течение лета. Таким образом, разница между основным и дополнительным индексом продолжает сужатся». «Supplemental goes mainstream», Google Search Central
В 2007 году Google официально отменил видимое обозначение Дополнительного индекса, интегрировав эти страницы с основным индексом, хотя разница между страницами с разной оценкой, вероятно, до сих пор неявно существует в системах индексации и рейтинга Google.
«Так, до 2010 года Google поддерживал два индекса по техническим причинам. Основной указатель обновлялся чаще и быстрее, а дополнительный индекс был для страниц меньшей важности, которые не нужно было обновлять так быстро». «Reminder: The Google Supplemental Index Has Not Existed In Over A Decade», Search Engine Roundtable
Google добавлял в основной индекс исключительно полезные, информативные и уникальные страницы. Если алгоритмы поисковика оценивали какую-то страницу сайта как неважную для основного индекса, она попадала в supplemental results. Украинские SEO-специалисты называли эти результаты еще частично созвучным сленгом «сопли Google».
Дополнительный индекс Google негативно влиял на ранжирование сайта, поскольку страницы, проиндексированные как неосновные, часто считались менее важными. Соответственно, рейтинг в результатах поиска был ниже, страницу не видели и не посещали пользователи.
А в 2009 году Google уже тестировал новый метод индексирования — Caffeine. Он заработал на полную в 2010 году, когда использование дополнительного индекса полностью прекратилось.
Supplemental results помогали отделить низкокачественный контент и дублирование содержимого, в частности, повторяющиеся описания на страницах одного и того же сайта. И хотя дополнительного индекса как такового уже не существует, тот же скопированный контент, как и искусственно сгенерированный, имеет более низкий приоритет и плохо влияет на видимость веб-ресурса в результатах поиска.
📌 Читайте статью: Что означает фраза Lorem Ipsum?
Как это работало?
- Google сканировал интернет с помощью ботов, индексируя содержимое веб-страниц. В основной базе данных он обрабатывал новое и наиболее релевантное содержимое.
- Алгоритмы Google выбирали, какой контент является не очень важным, не соответствующим запросам ЦА и ключевым словам, или просто устаревшим. Страницы с таким наполнением добавлялись во вторичный индекс.
- Обновление индекса в дополнительных результатах происходило значительно реже, чем в основных, поэтому приоритет таких страниц был ниже, как и рейтинг и видимость.
Уже более 15 лет результаты основного и дополнительного индексов объединяются на странице результатов поиска. При этом Google еще больше внимания уделяет релевантности контента, его уникальности, естественности и факторам E-E-A-T (экспертность, опыт автора, авторитетность и надежность).
Почему веб-страницы попадали в Google Supplemental Index?
Существовал ряд распространенных ошибок, которых следует избегать и сегодня. Ведь, хотя понятие дополнительного индекса уже давно не актуально, практически все факторы, которые приводили к попаданию страниц в Google Supplemental Index, плохо влияют на продвижение страниц и сейчас.
- Дублирование контента. Придирчивый фильтр Panda смотрит даже на дубли внутри сайта. Поэтому если у вас есть повторы контента на разных страницах, и на данный момент вы ничего с этим не можете сделать, закрывайте все неуникальные страницы от индексирования в файле robots.txt.
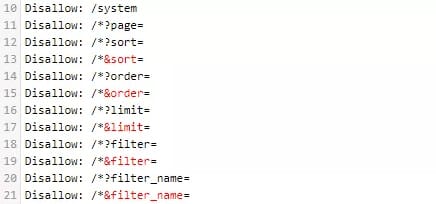
Директива Disallow запрещает индексацию.
- Плохо продуманная структура сайта, сложная навигация. Это плохо и для пользовательского опыта, так что регулярно проводите аудит сайта. Если сканеры поисковой системы не могут легко ориентироваться на веб-ресурсе, вероятно, они не проиндексируют некоторые страницы. Так что позаботьтесь о наличии XML-карты и поработайте над тем, чтобы структура сайта была максимально предсказуемой и удобной.
- Глубоко вложенные страницы. Этот критерий касается предыдущего пункта списка. Если для того, чтобы найти страницу, пользователю приходится кликать мышкой больше четырех раз, это будет негативно восприниматься и самими юзерами, и поисковиками. Упрощайте архитектуру, делайте важные страницы доступными.
- Низкий PageRank. Улучшайте показатель с помощью качественной ссылочной стратегии и ее последовательного внедрения. Это касается как бэклинков на авторитетных ресурсах, так и внутренней перелинковки.
- Незначительное содержание. Не публикуйте на странице одно-два предложения и тем более не оставляйте ее пустой. Сконцентрируйте свое внимание на создании качественного экспертного контента. Даже если это просто описания товаров или услуг. Они имеют свои правила написания, поэтому учитесь создавать различные типы текстов, инфографику, видео и в целом готовить классные материалы, которые Google высоко оценит, а посетители страницы – просмотрят или даже распространят.
- Редкие обновления тоже могут вызвать недоверие со стороны поисковых систем. Обновляйте контент. Например, к статье в блоге можно добавить цитату эксперта, интересное изображение или видеоролик.
- Полное отсутствие внешних ссылок делают сайт менее авторитетным. Соблюдайте баланс: чрезмерное использование партнерских ссылок, а особенно наличие на странице ссылок на сомнительные ресурсы — «красный флажок» для Google.
- Страница, тема которой существенно отличается от содержания сайта, также вызывает подозрения поисковиков. Аналогично со сгенерированными искусственным интеллектом текстами. Когда Supplemental Index еще существовал как таковой, проблемы искусственности еще не существовало, однако актуальной была заспамленность и низкая уникальность контента. Все это в сочетании важно и сейчас.
- Отсутствующие метатеги title, description или их повторы на сайте также могли загнать веб-страницы в дополнительный индекс.
- Причиной попадания страницы в supplemental index может быть и некорректная внутренняя перелинковка, и неправильная настройка файла Robots.txt. Аудит сайта позволяет выявить и устранить эти ошибки.
Причиной попадания страниц в дополнительный индекс может быть и неправильная внутренняя перелинковка, и неправильное размещение файла Robots.txt. Аудит сайта позволяет увидеть и усугубить эти проблемы.
📌 Читать статью: Как писать метатеги: Title, Description, H1
Как избегали попадания в Supplemental Index?
Чтобы поисковые системы рекомендовали пользователям веб-страницы сайта, следует регулярно работать с SEO. Ведь дополнительный индекс — далеко не единственная проблема, которая могла возникнуть у владельца веб-ресурса.
Последовательность в продвижении сайта позволит вам наращивать целевой органический трафик. Для этого выполняйте комплекс действий, которые ранее использовали для избежания попадания в Supplemental Index.
- Убедитесь, что на сайте нет скопированного с других ресурсов контента. Если такой есть, замените его уникальными статьями, изображениями, видео. Не забывайте о метатегах и ключевых словах.
- Проверьте качество ссылочной массы (количество бэклинков, их качество, релевантность). Используйте сервисы Google Search Console, Ahrefs (Domain Rating и Backlink Checker), Moz Spam Score.
- Для страниц, которые нельзя улучшить (да и не очень нужно), например, «Политика конфиденциальности», используйте тег «noindex». Таким образом они не будут индексироваться и не будут влиять на SEO-показатели веб-ресурса.
«Вы можете предотвратить появление нового содержимого в результатах, добавив слаг URL-адреса в файл robots.txt . Поисковые системы используют эти файлы, чтобы понять, как индексировать содержимое веб-сайта. Содержимое системных доменов HubSpot, содержащее hs-сайты, всегда устанавливается как no-index в файле robots.txt. Если поисковые системы уже проиндексировали ваше содержимое, вы можете добавить мета-тег «noindex» в HTML заголовок содержимого. Это позволит поисковым системам прекратить отображать его в результатах поиска». «Prevent content from appearing in search results», HubSpot
- Оптимизируйте внутреннюю перелинковку, а именно — добавляйте ссылки на важные страницы со страниц первого и второго уровня вложенности, а также из навигационного меню.
- Применяйте перенаправление 301 для постоянно перемещаемых страниц и канонических тегов.
- Важным фактором является скорость сайта. Обращайте особое внимание на то, нет ли проблем с загрузкой веб-ресурса и отдельных элементов на мобильных устройствах, а также ничего не «съезжает», работают ли формы и удобно ли их заполнять. Низкий показатель отказов демонстрирует поисковым системам, что сайт полезен для пользователей.
- Публикуйте качественный контент, соответствующий требованиям E-E-A-T. Содержание веб-страниц должно быть надежным, экспертным, авторитетным и отражать опыт автора. Прекрасно, если ваш копирайтер является специалистом в конкретной узкой сфере, о которой пишет. Глубокие знания сделают любые материалы более уникальными, ценными и естественными.
Отслеживайте эффективность с помощью инструментов Google Analytics и Google Search Console. Делайте это до и после каждого изменения, которое вы вносите на сайт.
Период, когда попадание в дополнительный индекс было реальным риском для владельцев сайтов давно прошел, однако все критерии оценки сайтов поисковиками остались актуальными. Более того — началась эпоха искусственного интеллекта, что существенно повлияло на специфику продвижения веб-ресурсов.
Если раньше контент должен был быть без спама и уникальный, то теперь добавился важный показатель — естественность, а точнее, отсутствие искусственно сгенерированного контента. Советуем проверять тексты на наличие ИИ не только в том случае, если вы создали статью в ChatGPT и отрерайтили ее, но также в тех случаях, когда написали материал самостоятельно.
Дело в том, что тексты без эмоциональной окраски, особенно на популярные темы, часто считываются программами как искусственно сгенерированные. Вероятно, это происходит из-за того, что чат-боты ИИ собирают информацию на разных сайтах, и если во многих источниках совпадают формулировки, ваши авторские предложения могут считаться неуникальными и сгенерированными. Проверяйте статьи в онлайн-сервисах Smodin, GPTZero, AI Detector или OpenAI.
Выводы
До 2007 года дополнительным индексом называли вторичную базу данных поисковой системы. В своем хранилище Google хранил веб-страницы, которые считал менее оригинальными и не очень полезными. Также это касалось тех страниц, которые редко обновлялись. Таким образом поисковая система пыталась обеспечивала более точные и ценные результаты поиска для пользователей.
В 2006 году Google начал накладывать на сайты меньше ограничений. Обновленные алгоритмы сканирования и индексации дополнительных результатов привели к тому, что в 2007 году дополнительный индекс был официально отменен. До 2010 года поисковая система по техническим причинам поддерживала оба индекса.
Поисковик до сих пор обращает внимание на качество содержимого страниц. Дополнительный индекс исчез, а критерии, по которым страницы попадали в него, остались. Добавились новые факторы, которые влияют на продвижение сайта негативно, например, искусственно сгенерированные тексты. Поэтому чтобы занимать в рейтинге Google высокие позиции, регулярно публикуйте на веб-ресурсе уникальный авторский контент и работайте над ссылочной массой сайта.
FAQ
Дополнительным индексом называли вторичную базу данных поисковых систем, в том числе Google. На сегодняшний день Google Supplemental Index не существует. Однако факторы, которые влияли на попадание страниц в «сопли Google», следует учитывать для оптимизации сайта.
Украиноязычные SEO-специалисты часто используют сленговое, подобное по звучанию название — «сопли Google».
С 2007 года Google официально не использует дополнительный индекс. Поисковик интегрировал дополнительные страницы с основным индексом.
-
Tags